ECW 2017 - Red Diamond
Pour la deuxième année consécutive, Thales et Airbus ont organisé un CTF à destination des étudiants européens: le challenge ECW. Tout comme l’année dernière, celui-ci est séparé en une épreuve qualificative individuelle (CTF Jeopardy classique) et une phase finale par équipe avec un format Attaque/Défense.
L’épreuve qualificative de cette année reprenait les catégories classiques de CTF: Web, Forensics, Crypto et Reverse.
Parmis les 4 challenges de reverse qui étaient proposés, voici la solution de celui qui m’a paru le plus intéressant mais également le plus compliqué à résoudre.
Le binaire qui nous est donné pour ce challenge est un PE x86-64, sans plus tarder on l’ouvre dans son désassembleur préféré pour voir un peu à quoi on a affaire.
On constate rapidement un nombre élevé de fonctions (un binaire de 6 Mo tout de même), cependant l’utilisation d’IDA permet de récupérer la quasi totalité des noms de fonctions et variables, ce qui simplifie grandement le travail.
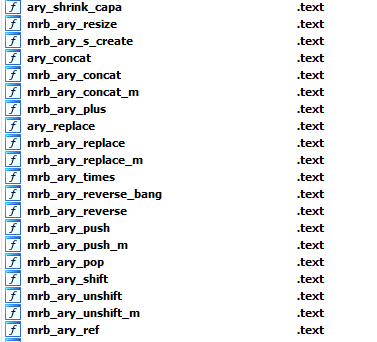
Comme la plupart des fonctions commencent par mrb, on fait un peu de Google pour voir à quoi ça fait référence et on trouve rapidement qu’il s’agit de MRuby, une implémentation plus légère du langage Ruby pouvant être embarqué dans un binaire écrit en C (voir MRuby pour plus d’infos).
Au point d’entrée de notre exécutable, on peut voir que plusieurs fonctions relatives à Cygwin sont appelées, signifiant que le binaire a été compilé avec ce dernier et qu’il sera nécessaire d’installer Cygwin si on veut pouvoir exécuter/débugger l’exécutable.
Ceci étant dit, on peut maintenant s’intéresser davantage au code du programme, et particulièrement la fonction f qui est la première fonction intéressante à être appelée.
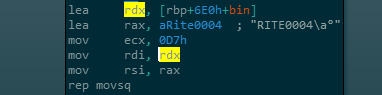
On peut voir sur la capture ci-dessus qu’un segment de données commençant par RITE0004 est copié en mémoire (dans la variable bin). Un peu de Google montre qu’il s’agit des premiers bytes d’un bytecode MRuby. Il est en effet possible de compiler un script Ruby (valable également en Python par exemple) pour qu’il puisse être exécuté plus rapidement. Cependant cela nécessite un programme tiers capable d’exécuter ces opcodes spécifiques, autrement dit une VM MRuby.
Afin de regarder plus précisément à quoi correspond ce bytecode MRuby, je l’ai extrait en utilisant ce bout de code IDAPython.
import idaapi
import struct
sea = ScreenEA()
mrb = open("reddiamond.mrb",'wb')
for i in range(0x6be):
mrb.write(struct.pack('B',Byte(sea+i)))
mrb.close()
En ouvrant le fichier reddiamond.mrb avec un éditeur hexadécimal, on observe des strings qui nous intéressent pas mal comme Let me check if you deserve a flag ... ou encore flag is:.
Le challenge est donc de reverser ce petit bout de bytecode pour comprendre comment le flag est généré. Pour cela, il y a 2 écoles:
- analyse statique: on utilise l’interpréteur MRuby (disponible ici) pour obtenir une traduction des opcodes et reverser statiquement à partir de là
- analyse dynamique: on essaye de comprendre comment fonctionne la VM pour débugger le bytecode et breaker aux endroits opportuns
Pour ma part, j’ai fini par utiliser les 2 méthodes après avoir passé un bout de temps à reverser statiquement chaque opcode, je pense malgré tout qu’il était possible de tout faire statiquement pour quelqu’un de familier avec les opcodes MRuby.
Après avoir téléchargé l’interpréteur MRuby (voir plus haut pour le lien), on peut l’utiliser de la manière suivante pour récupérer tous les opcodes traduits.
$ mruby --verbose -b reddiamond.mrb
irep 0x7fba3c702fd0 nregs=7 nlocals=3 pools=11 syms=12 reps=2
000 OP_LOADSELF R3
001 OP_STRING R4 L(0) ; "CRACKME!"
002 OP_SEND R3 :puts 1
003 OP_LOADSELF R3
004 OP_LOADSELF R4
005 OP_LOADL R5 L(1) ; 400000
006 OP_SEND R4 :rand 1
007 OP_SEND R3 :usleep 1
008 OP_LOADSELF R3
009 OP_STRING R4 L(2) ; "Let me check if you deserve a flag ..."
010 OP_SEND R3 :puts 1
[...]
Chaque ligne commençant par irep représente une fonction et les lignes numérotées en dessous représentent le code de la fonction (chaque ligne = 1 opcode). On dénote ainsi 6 fonctions distinctes.
irep 0x7fba3c702fd0 nregs=7 nlocals=3 pools=11 syms=12 reps=2
[...]
irep 0x7fba3c7034b0 nregs=25 nlocals=5 pools=10 syms=19 reps=1
[...]
irep 0x7fba3c703a80 nregs=8 nlocals=3 pools=0 syms=6 reps=0
[...]
irep 0x7fba3c703b70 nregs=3 nlocals=1 pools=0 syms=2 reps=2
[...]
irep 0x7fba3c703c30 nregs=5 nlocals=2 pools=0 syms=1 reps=0
[...]
irep 0x7fba3c703ce0 nregs=5 nlocals=2 pools=0 syms=1 reps=0
[...]
Outre nous indiquer la présence d’une fonction, cet en-tête donne également le nombre de registres (25 au max) utilisés dans la fonction ainsi que le nombre de variables locales et de symboles.
Comme l’entrypoint n’est pas précisé dans un MRB, on sait que la première fonction (0x7fba3c702fd0) représente notre main, ce qui paraît logique en voyant les strings affichées.
Sachant cela, on peut commencer à analyser chaque opcode pour voir un peu ce qui se passe dans cette fonction, pour cela 2 liens du repo Github de MRuby m’ont beaucoup servi (voir ici et ici)
Les premiers opcodes du main vont afficher quelques strings qui ne nous intéressent pas trop et vont également exécuter plusieurs fois la fonction usleep (probablement pour éviter un bruteforce du flag).
000 OP_LOADSELF R3
001 OP_STRING R4 L(0) ; "CRACKME!"
002 OP_SEND R3 :puts 1
[...]
007 OP_SEND R3 :usleep 1
008 OP_LOADSELF R3
009 OP_STRING R4 L(2) ; "Let me check if you deserve a flag ..."
010 OP_SEND R3 :puts 1
[...]
017 OP_SEND R3 :usleep 1
[...]
Ce qui nous intéresse davantage se situe à l’opcode 27 où la fonction found? est appelée. Selon le résultat de cette fonction, 2 comportements sont possibles (OP_JMPNOT):
- soit le programme jump à l’opcode 46, affiche la string “NO :(” et quitte le programme
- soit le programme continue à l’opcode 29, afficher la string “YES :)” avec notre flag et quitte le programme
[...]
027 OP_SEND R3 :found? 0
028 OP_JMPNOT R3 046
// Good boy
029 OP_LOADSELF R3
030 OP_STRING R4 L(5) ; "YES :)"
031 OP_SEND R3 :puts 1
032 OP_GETCONST R3 :MD5
033 OP_STRING R4 L(6) ; "\342\235\250\342\225\257\302\260\342\226\241\302\260\342\235\251\342\225\257\357\270\265\342\224\273\342\224\201\342\224\273"
034 OP_GETGLOBAL R5 :$salt
035 OP_ADD R4 :+ 1
036 OP_SEND R3 :md5_hex 1
037 OP_MOVE R1 R3 ; R1:flag
038 OP_LOADSELF R3
039 OP_STRING R4 L(7) ; "\tflag is: '"
040 OP_MOVE R5 R1 ; R1:flag
041 OP_STRCAT R4 R5
042 OP_STRING R5 L(8) ; "'"
043 OP_STRCAT R4 R5
044 OP_SEND R3 :puts 1
045 OP_JMP 049
// Bad boy
046 OP_LOADSELF R3
047 OP_STRING R4 L(9) ; "NO :("
048 OP_SEND R3 :puts 1
049 OP_JMP 069
[...]
Au premier abord, on pourrait se dire que la longue string est peut-être notre flag, cependant une rapide lecture des opcodes montre que cette string est en fait hashée (MD5) avec la variable globale salt pour donner le flag.
flag = md5($salt+"\xE2\x9D\xA8\xE2\x95\xAF\xC2\xB0\xE2\x96\xA1\xC2\xB0\xE2\x9D\xA9\xE2\x95\xAF\xEF\xB8\xB5\xE2\x94\xBB\xE2\x94\x81\xE2\x94\xBB")
Il faut donc aller regarder un peu du côté de la fonction found? pour voir où est-ce que cette variable globale est initialisée, c’est aussi là que l’analyse statique devient plus complexe…
Le début de la fonction est assez compliqué pour pas grand chose au final, tout ce que fait ce petit bout de code est de générer un tableau comprenant les valeurs “utf-0” “utf-1”… jusqu’à “utf-30” pour récupérer uniquement “utf-8” et “utf-16”.
[...]
// Génération du tableau dans R2
001 OP_STRING R5 L(0) ; "utf-0"
002 OP_STRING R6 L(1) ; "utf-9"
003 OP_RANGE R5 R5 0
004 OP_SEND R5 :to_a 0
005 OP_STRING R6 L(2) ; "utf-10"
006 OP_STRING R7 L(3) ; "utf-30"
007 OP_RANGE R6 R6 0
008 OP_SEND R6 :to_a 0
009 OP_ADD R5 :+ 1
010 OP_MOVE R2 R5 ; R2:"\302\265"
011 OP_LOADSELF R5
012 OP_GETCONST R6 :Iconv
013 OP_MOVE R7 R2 ; R2:"\302\265"
// Stockage de "utf-8" dans R7
014 OP_LOADI R8 8
015 OP_SEND R7 :[] 1
016 OP_MOVE R8 R2 ; R2:"\302\265"
// Stockage de "utf-16" dans R8
017 OP_LOADI R9 16
018 OP_SEND R8 :[] 1
[...]
La suite du code montre que le programme extrait ces 2 strings pour convertir la string ARGV[2] de UTF-16 en UTF-8, en utilisant la fonction suivante.
Iconv.conv(to, from, str)
[...]
// Stocke la string "ARGV[2]" en UTF-16 dans les registres R11 à R24
021 OP_LOADI R11 0
022 OP_LOADI R12 65
023 OP_LOADI R13 0
024 OP_LOADI R14 82
[...]
035 OP_ARRAY R9 R9 16
036 OP_STRING R10 L(4) ; "C*"
037 OP_SEND R9 :pack 1
// Appel de la fonction conv de la classe Iconv (voir opcode 12)
038 OP_SEND R6 :conv 3
[...]
La suite du programme consiste à récupérer la valeur contenue dans ARGV[2] qui ne correspond pas au premier mais bel et bien au second argument donné au programme (le premier argument n’est donc pas utilisé par le programme).
Le programme doit donc être exécuté de la manière suivante pour obtenir le flag.
$ ./86288dbbdadbe4d7e04dc1a4c4603f5b.exe <premier_arg_osef> <second_arg_clé>
Une fois que le programme a récupéré notre input, il va prendre uniquement les 8 premiers caractères de celui-ci et les stocker dans un tableau, puis vérifier chacun d’entre eux de manière différente.
[...]
051 OP_LOADI R6 0
052 OP_LOADI R7 7
// Range de 0 à 7 par pas de 1
053 OP_RANGE R6 R6 0
// R5 contient notre input, le range est donc appliqué sur celui-ci pour ne récupérer que les 8 premiers caractères dans un tableau
054 OP_SEND R5 :[] 1
// Le tableau contenant les 8 premiers caractères est stocké dans R3
055 OP_MOVE R3 R5
[...]
[...]
058 OP_MOVE R5 R3 ; R3:"\302\244"
059 OP_SEND R5 :first 0
060 OP_STRING R6 L(5) ; "W"
061 OP_EQ R5 :== 1
062 OP_MOVE R4 R5 ; R4:"\302\247"
063 OP_JMPNOT R5 068
[...]
Le premier caractère est très facile à comprendre, le programme va simplement utiliser la fonction first pour récupérer le premier caractère du tableau et le comparer à W, le retour de l’égalité est placé dans R4 (qui correspond à la valeur de retour de la fonction) puis il jump à l’opcode 68 si l’égalité n’est pas vérifiée. Ce dernier correspond au OP_JMPNOT du caractère suivant qu’il va suivre également, et ainsi de suite jusqu’à la fin de la fonction pour finalement retourner la valeur 0.
[...]
064 OP_MOVE R5 R3 ; R3:"\302\244"
065 OP_SEND R5 :last 0
066 OP_STRING R6 L(6) ; "a"
067 OP_EQ R5 :== 1
068 OP_MOVE R4 R5 ; R4:"\302\247"
069 OP_JMPNOT R5 077
[...]
Le second caractère est en réalité le dernier puisque le programme utilise la fonction last, celui-ci est comparé à a, puis la même routine est appliquée selon le résultat de l’égalité.
[...]
070 OP_MOVE R5 R3 ; R3:"\302\244"
071 OP_LOADI R6 1
072 OP_ADDI R6 :+ 1
073 OP_SEND R5 :[] 1
074 OP_MOVE R6 R3 ; R3:"\302\244"
075 OP_SEND R6 :first 0
076 OP_EQ R5 :== 1
077 OP_MOVE R4 R5 ; R4:"\302\247"
078 OP_JMPNOT R5 085
[...]
Celui-ci commence déjà à devenir plus compliqué, en convertissant les opcodes en quelque chose de plus compréhensible ça donne la séquence suivante:
- R6 = 1
- R6 += 1
- R5 = input[R6]
- R6 = first(input)
- R5 == R6 ?
Cela revient finalement à comparer le troisième caractère de notre clé avec W.
[...]
079 OP_MOVE R5 R3 ; R3:"\302\244"
080 OP_LOADI R6 1
081 OP_SEND R5 :[] 1
082 OP_LOADI R6 0
083 OP_SEND R6 :to_s 0
084 OP_EQ R5 :== 1
085 OP_MOVE R4 R5 ; R4:"\302\247"
086 OP_JMPNOT R5 095
[...]
Les instructions ci-dessus peuvent facilement se traduire de la manière suivante:
- R6 = 1
- R5 = input[R6]
- R6 = to_s(0)
- R5 == R6 ?
Un peu de google montre que la fonction to_s convertit simplement un integer en string, donc le deuxième caractère est 0.
[...]
087 OP_MOVE R5 R3 ; R3:"\302\244"
088 OP_LOADI R6 3
089 OP_SEND R5 :[] 1
090 OP_SEND R5 :to_i 0
091 OP_SUBI R5 :- 1
092 OP_LOADI R6 2
093 OP_ADDI R6 :+ 2
094 OP_EQ R5 :== 1
095 OP_MOVE R4 R5 ; R4:"\302\247"
096 OP_JMPNOT R5 103
[...]
Encore une fois on peut représenter le code de la manière suivante:
- R6 = 3
- R5 = input[R6]
- R5 = to_i(R5)
- R5 -= 1
- R6 = 2
- R6 += 2
- R5 == R6 ?
À l’inverse de la fonction to_s, la fonction to_i convertit une string en integer, le programme va donc chercher le quatrième caractère de notre input, le convertir en integer et lui soustraire 1 pour finalement le comparer à 4. Le quatrième caractère est donc 5.
[...]
097 OP_MOVE R5 R3 ; R3:"\302\244"
098 OP_STRING R6 L(7) ; "4"
099 OP_SEND R6 :to_i 0
100 OP_SEND R5 :[] 1
101 OP_STRING R6 L(8) ; "9"
102 OP_EQ R5 :== 1
103 OP_MOVE R4 R5 ; R4:"\302\247"
104 OP_JMPNOT R5 113
[...]
Toujours le même raisonnement, le cinquième caractère est donc 9, voici une traduction sous forme de pseudo-code.
input[to_i("4")] == "9" ?
[...]
105 OP_MOVE R5 R3 ; R3:"\302\244"
106 OP_LOADI R6 5
107 OP_LOADI R7 -1
108 OP_RANGE R6 R6 0
109 OP_SEND R5 :[] 1
110 OP_SEND R5 :first 0
111 OP_STRING R6 L(9) ; "("
112 OP_EQ R5 :== 1
113 OP_MOVE R4 R5 ; R4:"\302\247"
114 OP_JMPNOT R5 122
[...]
Celui-ci se veut un peu plus pénible à comprendre, l’idée derrière consiste à générer un range allant de 5 à 0 par pas de -1 (instructions 106 à 108), et d’appliquer ce range à notre input pour obtenir un tableau inversé des 6 premiers caractères de notre clé.
Une fois ce tableau obtenu, le premier élément de ce dernier (correspondant au 6e caractère de l’input) est comparé au caractère (.
[...]
115 OP_MOVE R5 R3 ; R3:"\302\244"
116 OP_LOADSYM R6 :[]
117 OP_LOADI R7 -2
118 OP_SEND R5 :send 2
119 OP_SEND R5 :to_f 0
120 OP_LOADI R6 8
121 OP_EQ R5 :== 1
122 OP_MOVE R4 R5
[...]
Après avoir fait un peu de google pour comprendre que la fonction to_f convertit un integer/string en float et qu’un tableau peut être indexé en sens inverse avec des indices négatifs, ce caractère ne présente aucune difficulté.
to_f(input[-2]) == 8 ?
Le septième caractère est donc 8, ce qui fait que nous avons pu récupérer les 8 premiers caractères de la clé, c’est à dire W0W59(8a.
Cependant, la fonction ne s’arrête pas là et c’est ici que les problèmes commencent.
L’analyse des opcodes en statique commence à montrer ces limites lorsqu’il faut comprendre la séquence d’instructions suivantes.
[...]
123 OP_LOADI R5 8
124 OP_LAMBDA R6 I(+1) block
125 OP_SENDB R5 :times 0
126 OP_MOVE R5 R4
127 OP_JMPNOT R5 132
[...]
On peut voir que la fonction _times_ est appelée pour répéter un bloc de code 8 fois, le problème est que ne nous savons pas de quel bloc il s’agit.
[...]
132 OP_MOVE R4 R5 ; R4:"\302\247"
133 OP_SETGLOBAL :$salt R3 ; R3:"\302\244"
134 OP_RETURN R4 normal ; R4:"\302\247"
Si ce bloc de code retourne 0, le programme jump à l’instruction 132 qui stocke notre input dans la variable globale salt et termine la fonction en retournant 0.
[...]
128 OP_MOVE R5 R2 ; R2:"\302\265"
129 OP_SEND R5 :size 0
130 OP_LOADI R6 16
131 OP_EQ R5 :== 1
[...]
Il faut donc que ce bloc retourne _Vrai_ pour obtenir le flag, si c’est le cas, la taille de notre input est comparée à 16 avant de poursuivre.
Comme nous avons les 8 premiers caractères et que le bloc de code (qui nous est inconnu) est exécuté 8 fois, on peut supposer que cette routine doit vérifier un caractère à la fois à partir du 9ème.
Il nous faut juste savoir ce qui est exécuté et c’est là que l’analyse dynamique entre en jeu !
L’analyse dynamique implique d’exécuter le programme, il faut donc installer cygwin au préalable pour pouvoir lancer le challenge.
Personnellement, j’ai choisi d’utiliser gdb pour debugger le binaire puisqu’il est intégré dans cygwin.
Comme précisé précedemment le binaire doit être exécuté de la manière suivante si on veut avoir une quelconque chance d’obtenir le flag.
$ ./86288dbbdadbe4d7e04dc1a4c4603f5b.exe <premier_arg_osef> <second_arg_clé>
# ou dans gdb
$ gdb ./86288dbbdadbe4d7e04dc1a4c4603f5b.exe
(gdb) r <premier_arg_osef> <second_arg_clé>
Sachant cela, revenons dans IDA pour comprendre comment on va pouvoir breaker sur une instruction particulière de notre bytecode.
Lorsqu’on analyse un binaire protégé par une VM, une des premières choses à comprendre est de voir comment celle-ci va aller chercher une instruction en mémoire (le dispatcher), puis comment celle-ci va être décodée (pour récupérer l’opcode et les opérandes) et enfin comment le bon handler (le code natif correspondant à l’opcode, il y en a un pour chaque opcode) va être appelé. Une fois qu’on est en possession de ces informations, on sait dans quelle variable le pointeur d’instruction est stocké (ce qui nous permet de breaker sur n’importe quelle instruction) et on sait où sont nos opérandes.
En résumé une VM est une grosse boucle qui va effectuer les actions suivantes.
- Prendre une instruction en mémoire (là où le bytecode a été mappé).
- Décoder l’instruction pour récupéré l’opcode et les opérandes.
- Exécuter le handler correspondant à l’opcode.
- Recommencer en prenant l’instruction suivante.
Dans notre cas, il faut jeter un coup d’oeil à la fonction mrb_vm_exec qui comporte notamment les différents handlers des opcodes. Comme IDA récupère tous les symboles, on peut voir qu’au début de la fonction, la variable pc est initialisée avec le registre r9.
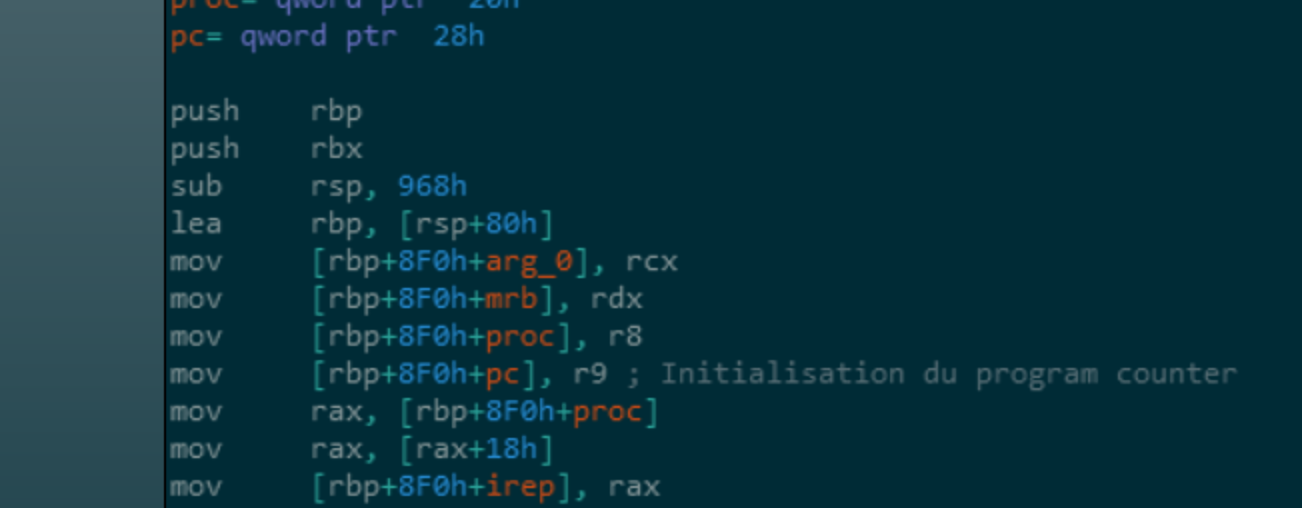
Cette variable correspond au Program Counter qui est notre pointeur d’instruction. Autrement dit, on peut se servir du contenu du registre r9 pour breaker au moment où le bytecode MRuby commence à être exécuté.
Comme c’est la variable pc qui contient notre pointeur d’instruction, on peut regarder à quel moment elle est mise à jour pour passer à l’instruction suivante. Il s’agit d’un point particulièrement important car il existe plusieurs manières de gérer ce point là:
- soit il existe un dispatcher qui gère la mise à jour du pointeur d’instruction et dans ce cas chaque handler va jumper vers ce dispatcher une fois fini pour qu’il puisse récupérer et décoder l’instruction suivante;
- soit chaque handler gère la mise à jour du pointeur d’instruction et le décodage de l’instruction et dans ce cas on passe directement de handler à handler.
Pour distinguer les 2, il suffit simplement de regarder les cross-références de la variable pc dans IDA. Dans notre cas, on constate rapidement qu’elle est mise à jour dans chaque handler et qu’on se trouve donc dans le second cas. Comme les instructions sont alignées sur 32-bits en MRuby, le pointeur d’instruction est incrémenté de 4 à chaque instruction.
Sachant cela, on peut désormais breaker à l’instruction que l’on souhaite en mettant un premier breakpoint conditionnel (voir ici pour la doc) pour breaker au début du bytecode, à partir de là on peut récupérer l’adresse mémoire à laquelle on retrouve notre pointeur d’instruction, puis mettre un watchpoint conditionnel (voir ici) sur ce dernier pour breaker à l’instruction que l’on souhaite.
Il y a toutefois un bémol à cette technique, il y a plusieurs instructions qui sont strictement identiques (que ce soit l’opcode ou les opérandes). Dans ce cas, le seul moyen de savoir où l’on se situe dans le flot d’instructions est de regarder les instructions précédentes et suivantes pour se repérer. Sinon, une bonne solution est d’avancer dans le code petit à petit pour être sur de s’y retrouver.
Un exemple pour illustrer tout ça. Mettons que je veuille breaker à la 3ème instruction du main.
La première étape va consister à breaker sur le début du programme en utilisant les commandes suivantes (l’adresse 0x1004350EC correspond à l’instruction initialisant le pointeur d’instruction dans la fonction vm_mrb_exec et 0x01800006 correspond à la première instruction).
(gdb) b *0x1004350EC
(gdb) condition 1 *$r9 == 0x01800006
(gdb) r <premier_arg_osef> <second_arg_clé>
On peut alors récupérer l’adresse mémoire où se trouve la variable pc (0xffffc298 dans mon cas) pour créer notre watchpoint conditionnel. Le pointeur d’instruction est initialisé à 0x60009d170, donc notre 3ème instruction à laquelle on veut breaker est à 0x60009d178.
(gdb) watch *0xffffc298
(gdb) condition 2 *0xffffc298 == 0x9d178
(gdb) c
Et on se retrouve ainsi au moment où le pointeur d’instruction est mis à jour à la fin du handler de la seconde instruction :-)
Si on revient maintenant au blocage sur l’analyse statique, il nous suffit d’utiliser cette technique pour breaker sur l’instruction 125 de la fonction found?. Puis de breaker sur l’instruction suivante (en incrémentant de 4 la condition de notre watchpoint) pour voir quel handler est appelé.
[...]
125 OP_SENDB R5 :times 0
[...]
Finalement, on se rend compte que le bloc qui est appelé est en réalité la 3ème fonction du bytecode (voir ci-dessous).
irep 0x7fd0a4d06620 nregs=8 nlocals=3 pools=0 syms=6 reps=0
000 OP_ENTER 1:0:0:0:0:0:0
001 OP_GETUPVAR R3 4 0
002 OP_JMPNOT R3 015
003 OP_GETUPVAR R3 2 0
004 OP_MOVE R4 R1 ; R1:n
005 OP_SEND R3 :[] 1
006 OP_GETUPVAR R4 2 0
007 OP_MOVE R5 R1 ; R1:n
008 OP_SEND R5 :-@ 0
009 OP_SUBI R5 :- 1
010 OP_SEND R4 :[] 1
011 OP_MOVE R5 R1 ; R1:n
012 OP_ADDI R5 :+ 1
013 OP_SEND R4 :^ 1
014 OP_EQ R3 :== 1
015 OP_SETUPVAR R3 4 0
016 OP_RETURN R3 normal
Cette fonction va donc être appelée 8 fois d’affilée (fonction times vu précédemment) pour tester les 8 caractères restants de notre clé.
Maintenant qu’on sait quelle fonction est appelée, il ne reste plus qu’à l’analyser pour voir ce qu’elle fait.
L’opcode OP_GETUPVAR va aller chercher la valeur du registre de la fonction appelante selon l’opérande qui est utilisé.
Par exemple pour l’instruction 1 de notre bloc, c’est la valeur de R4 de la fonction found? qui va être stockée dans R3.
[...]
001 OP_GETUPVAR R3 4 0
002 OP_JMPNOT R3 015
[...]
Pour rappel, cette valeur correspond au résultat de l’égalité du 8ème caractère (le 7ème en fait si vous vous souvenez bien) de notre input. Comme cette instruction est suivie du opcode OP_JMPNOT, si l’égalité est fausse, le programme jump directement à l’instruction 15 du bloc qui stocke la valeur de R3 dans le registre R4 de la fonction found? et termine l’exécution de la fonction.
Si notre caractère est bon, la fonction continue à l’instruction 3.
[...]
003 OP_GETUPVAR R3 2 0
004 OP_MOVE R4 R1 ; R1:n
005 OP_SEND R3 :[] 1
[...]
Cette fois-ci, OP_GETUPVAR permet de récupérer le R2 de found? qui correspond à notre input en entier (pas juste les 8 premiers caractères) défini à l’instruction 49 de la fonction found?. Grâce aux symboles on peut voir que R1 représente n, c’est-à-dire l’itération de la fonction times, il va donc varier de 0 à 7 par pas de 1 à chaque exécution de la fonction. Comme il s’agit de la première exécution, R1 est vide donc le premier caractère de notre input est stocké dans R3 (c’est-à dire le caractère W).
[...]
006 OP_GETUPVAR R4 2 0
007 OP_MOVE R5 R1 ; R1:n
008 OP_SEND R5 :-@ 0
009 OP_SUBI R5 :- 1
010 OP_SEND R4 :[] 1
[...]
Ensuite, notre clé est à nouveau récupérée pour être stockée dans R4 en utilisant à nouveau l’opcode OP_GETUPVAR, puis R1 (qui vaut toujours 0) est stocké dans R5 et l’instruction 8 converti la valeur de R5 en valeur négative (1 en -1 par exemple). Cependant, comme R5 vaut 0, il reste à 0. Finalement, on soustrait 1 à R5 (ce qui donne -1) pour récupérer le dernier caractère de notre input (le 16e donc) et le stocker dans R4.
[...]
011 OP_MOVE R5 R1 ; R1:n
012 OP_ADDI R5 :+ 1
013 OP_SEND R4 :^ 1
014 OP_EQ R3 :== 1
[...]
Finalement, l’itérateur (R1) est à nouveau copié dans R5, auquel on ajoute 1, puis on XOR le tout avec R4 qui correspond au dernier caractère de notre clé. Cela a simplement pour effet d’ajouter 1 à l’ordinal de ce dernier. Le résultat est ensuite comparé à R3 correspondant au premier caractère de la clé. On peut ainsi rapidement en déduire que le dernier caractère de la clé est V.
Comme R1 est incrémenté à chaque exécution de la fonction, on comprend que les caractères de la seconde partie de la clé sont vérifiés à partir de la première partie. Pour résumer tout ça, voici une implémentation du check des 8 derniers caractères en pseudo-code.
is_equal = 1 # on part du principe que le 8e caractère est bon
for i in range(8):
if is_equal:
a = input[-i-1]^(1+i)
if input[i] != a:
is_equal = 0
return is_equal
Le déroulement de cette boucle nous permet enfin de récupérer la clé en entier, soit: W0W59(8ai?.\<1T2V
Il ne reste plus qu’à valider pour voir si on arrive à obtenir le flag, en prenant le soin de escape les caractères spéciaux pour Bash avec des backslashes.
$ /cygdrive/c/Users/john/Desktop/86288dbbdadbe4d7e04dc1a4c4603f5b.exe give_me_the_flag W0W59\(8ai?.\<1T2V
CRACKME!
Let me check if you deserve a flag ...
YES :)
flag is: '983b428e721bcfceabf6c77d9e819d8d'
Et miracle, ça marche !! :-)
C’est tout pour ce write-up (bien joué à tous ceux qui ont eu le courage de tout lire), selon moi c’était sans doute un des challenges les plus durs de ce CTF mais aussi l’un des plus enrichissant !
Je remercie les auteurs du chall qui ont dû se casser la tête pour le créer, mais également tous ceux qui ont organisé le CTF d’une manière générale, j’espère que c’est un event qui pourra perdurer.
Merci à scud pour l’aide sur la compréhension de la VM MRuby, je n’aurais sans doute pas réussi à finir sans ça.